How the Terminator could save everyone. You included.
Monday mornings are the worst.
It feels like everything decides to go wrong — your alarm, power outages, car accidents, new projects at work. I’m betting there’s some magical voodoo running behind the scenes, trying to make people as miserable as possible.
Imagine, if you could rid all these problems by waving a wand. It would be amazing — you’d be able to actually use your devices, have a faster commute, and be able look at doggo pictures at work.🐶
But how? You can’t control power outages, reckless driving, or more work. It’s not like we can go out and solve all these problems ourselves. So much for our “wave a wand” fix. 😢
Hold up! Don’t get discouraged yet.
Let me explain — we can’t solve them…but the terminator can.
Please welcome…the Terminator.
You heard (or read) me right.
Depending on how we use it, The Terminator can solve dozens of problems — poverty, global warming, healthcare access, you name it. And damn well at that.
Still confused? We’re talking about the tech behind the terminator — Artificial Intelligence.
But wait — isn’t AI a world-ending technology? We can’t trust it to solve our largest problems!
You’re right. How can we trust something when we don’t know how it works?Let’s break it down.
AI is a field of computer science that tries to get machines to think like humans. It’s difficult to do, but it manages to do this with a bunch of algorithms– letting it learn from its own mistakes. Cool, isn’t it?
And, contrary to popular belief, AI isn’t the terminator…yet.
When we get to world destroying AI, we’re talking about AGI — a special kind of AI that can do everything better than we can. That’s why it’s called “Artificial General Intelligence.” It’s like a chef that can cook, clean, set tables, take orders, and read cookbooks at the same time (sorry staff, you’ve been replaced). 👩🍳
Since it’s general-purpose, AGI can do multiple tasks without being repeatedly trained. Almost like a certain species that’s reading this article…
But, there’s more. If this technology existed today, it would eliminate the need for human work, and billions of jobs too.
Or at least, that’s what a lot of people think. It might just cause a major shift in both resource production and life, benefitting us all. There’s really no way to tell, not now at least.
Thankfully, AGI is a long way off from today. Present day AI are like specialists — algorithms that have been trained thousands of times to do one thing really well, like recommend posts or drive cars. Swap them around, and you have utter chaos (you do NOT want an Instagram algorithm driving your car).
But then, why is AI commonly viewed so negatively? Let me explain.
The biggest problem with AI isn’t the tech, workforce, or implementation (though those are pretty big ones) — it’s public perception.
Look at Sci-fi movies over the last three decades, and you’ll see exactly what I’m talking about. Thanks to movies like “The Terminator”, “The Matrix”, and social media, people (probably you too) think AI is going to enslave and kill us all.
What this creates is a massive disconnect from reality — right now, we’re still stuck in the “Whoops, my AI thought a cat was a dog” phase, while the media is all the way down the “AI will take over the world!” rabbit hole. We’ve made progress, yeah (AI can detect COVID from cough audio, pretty insane), but nowhere near the world-destroying phase.
But wait, there’s more.
AI has tonnes of problems. So, it needs responsible development and more smart people working on it — not misinformation that can lead to the elimination of this technology.
Stopping AI development would be like using a hang glider to get places when there’s a plane available — terribly ineffective, and generally not a good idea. Do we really want to eliminate everything about AI? The good with the bad?
Solving the problems with this technology means getting rid of ignorance — something that can only be done with knowledge. Modern AI has really only been around for 15 years or so, so it’s perfectly understandable that most people would think of it like a black box. And, when we don’t understand something, we tend to avoid it and assume the worst. It’s just human nature.
So, I’m going to remove the confusion around AI and reveal it’s inner workings — while using emojis and references, of course. 😜
Buckle up in your self driving cars — this is going to be a long ride.🚗
How in Cyberspace does AI work?
Imagine a classroom, with a teacher that can test but not teach, and one student to look after. The student has only one metric that can tell him how he’s doing — his test score (since he literally wasn’t taught anything). His only goal is to increase his test scores and decrease mistakes.
At first, our student fails miserably — he literally has no clue what to answer for each question. Remember that he just knows the test score, and the questions and answers.
By all respects, the student shouldn’t be able to perform well. Just giving a kid the right answers and questions won’t actually get them to learn the material, right?
But here’s the best part — over time, he actually gets better.
He gives test after test and receives score after score, with answers to guide him along the way — until one day, he manages to score 90% on a test.
You’re probably wondering how that’s possible. It’s not liked the student knows anything — he’s just been tested over and over again, with no learning material of sorts.
So, how did this happen? It’s pretty simple, but also mind-blowing. Each time he gave the test, he made a small improvement. And by small, I mean really small — like maybe understanding that + means to add. That may not seem like much — but replicate it over hundreds of tests, and those small improvements add up — now, he can understand multiplication, division, subtraction, and put them together.
And that, forms the foundation of AI.
For example, let’s say we wanted an AI to recognize cats and dogs. Initially, our AI is like the student — it has absolutely no clue what to do, so it resorts to random guessing. It only has access to its own answer, the right answer, and how much it got it wrong by. So, it makes small changes based on these metrics.
Now here comes the good part. Just like our student, AI can learn from its mistakes and then make tiny changes, getting a little better each time. Those tiny steps then accumulate into leaps and bounds, to a point where it can classify cats and dogs! The student related “+” to addition, and the AI has associated whiskers and sharp ears for cats, and maybe longer faces for dogs (as an example).
Armed with these insights, the real task begins — classifying never-before-seen images. And guess what? It manages to classify a heck of a lot of them correctly!
Our AI is now like the student post-testing — able to use its insights for things it’s never seen before. (except it’s for cats and dogs — not algebra and math). This is called generalization, and it’s why we train AI in the first place.
Generalize: applying past learnings to analyze things never seen before — hopefully better than us. If AI couldn’t generalize, it would be pretty useless.
Think about that for a second. We just made a metal machine to tell cats apart from dogs. From, mind you, nothing but repeated tiny changes! That right there, is an absolutely insane achievement.
But we’ve still left a question unanswered — how does AI know what to change? Computers can’t think about the contents of images or text. They aren’t people.
And, how on Earth does it make improvements? Does it rebuild itself? Look at a different part of the image? Randomly change stuff? It seems like a black box.
The answers to all of these questions, literally lies in our own minds — Neural networks.
Your brain is an AI. Kind of.
Wait what? What does my brain have to do with an AI?
Patience, young Padawan. What do you think makes up your mind?
The answer to that is neurons — tiny cells that, when multiplied by 86 BILLION, make up everything you call…you.
They control everything you do — from doing math to wanting to eat cake. While they can do pretty cool stuff together, each neuron is actually very simple.
A neuron is like a function — it takes in an input, transforms it, and outputs it — all with electrical signals.
Other neurons then use those outputs as their inputs, making up hundreds of tiny chains of inputs and outputs! How cool is it, that you’re basically just a bunch of stacked functions?
Welcome to neural networks!
Neural networks operate a lot like the brain, except that their neurons operate on numbers instead of electric signals. Oh, and they only have a couple thousand neurons, instead of a couple dozen billion.

Each neuron (called a perceptron), takes in multiple numbers, transforms them, and then outputs them. The transformation is done via an activation function.
What? What’s that?
Let’s say that you wanted to find the probability (which can only exist between 0 and 1) that something was an apple (very innovative). Since a perceptron doesn’t have any limits on how high (or low) it can go (number limbo!), you’re basically going to get a not-so-helpful output.
“Hey, perceptron, what’s the probability that this is a picture of an apple?”
“Beep, 21924932402.23.”
We need some way of transforming this (unhelpful) output between 0 and 1. This is where activation functions come in — transformations on the output that constrain values (fitting them in a certain range). In our case, a nifty function that does this is the sigmoid — smaller numbers become close to 0, and larger ones become close to 1. So, the nonsense that the network outputted earlier would be pretty damn near 1.
One perceptron is cool, but we can do better. Let’s stack a whole bunch up in layers, where they can all share outputs!
Sound familiar? It’s like what our brains do, hence the name neural networks.

Terminology Time!
The first layer is called the input layer — it’s where we’ll input data in the network.
The last layer is the output layer — where we’ll collect results from the network.
Everything in between these two layers is called a hidden layer, because it’s well…hidden from us. When training this network, we don’t see the hidden layer(s) — we just give inputs and take the end outputs.
The arrangement of the layers is called its architecture (this one has 8 neurons in the input, 9 in the hidden ones, and 4 in the output). It’s called a deep neural network if it has more than 1 hidden layer.
Phew! Those were a lot of terms.
Together, these layers can compute huge equations and solve diverse challenges!
So, how do they understand information?
Data put in through the input layer gets transformed by thousands of weights and biases in the first hidden layers. Weights and biases numbers that decide the importance of an input (I know, brilliant explanation). Basically, imagine a judge that always believes one witness more than another — that’s what biases and weights do. Except the judge is the perceptron, and the witnesses are the inputs.
Anyway, the activation function then takes these values, and outputs the last set of numbers. Then, the process begins again, until we get to the output layer (which is a little special).
The output layer is the same as the others, except for one thing: this where we measure error. To help us, we have different errors for different purposes (like cross entropy for probabilities) — these assign numbers to the net’s mistakes (and boy, does it make a lot).
This entire process of inputs, transformations, and outputs is called forward propagation, because the inputs…forward propagate themselves through the entire network (brilliant explanation part 2).
But, it’s only half the story. We can run inputs and calculate error with this, but we can’t make the net better. How do we improve it with just input data, output data, errors, and weights and biases?
Well, it turns out that we can — with one special ingredient.
If networks calculate their outputs from neurons, and neurons calculate their outputs from weights and biases, then we can change the output by changing the weights and biases.
And this, is where the backpropagation algorithm comes in — kind of like forward propagation, except it moves backwards through the net (from the output to the input). Get it? Backpropagation? 😂
The point of doing this is to find the weights that most affect the output — like if a certain weight might be causing a huge amount of error. Backprop’s job is to tack these rogue weights down and change them. Now this is the real terminator!
How does it do this? Well, it’s all thanks to a little something called the chain rule in calculus.

Remember, the goal of the network is to find the combination of weights + biases that minimize error. For explanation’s sake, let’s say that we have one weight in our network, and plot it on a graph with the error:

As you can see, there’s a point where the error’s the smallest — the global minima. That’s where we want to be, but we don’t know what value to set the weight to get there — just the current weights and error. We only know a part of this graph — not the whole picture. So, we need to go down this curve, to get to the bottom of things (pun intended 😊).
Here’s the best part — the fastest way to go up a slope (the error) in calculus, is the gradient.
Think about it — we want to descend the mountain. So, if we took the opposite of the gradient, we can find the fastest way to get down.
And what’s the opposite of a number? Its negative! By taking the negative gradient of each neuron, we can find the fastest way to reduce the error!
Small problem — this works for each neuron, yeah. But how are we going to find the gradient of the entire network?
And this, is where our beloved chain rule comes in — it basically says that the derivative of a combined function, is equal to the derivatives of the sub-functions.
Basically, the derivatives of each function, can be combined to give us the derivatives of the total function. If we want to calculate the derivative of the whole pie, we can do it by finding the derivative of each slice. Make sense?
This rule is perfect — we can just calculate the derivatives of all the nodes, and then combine them to get the total gradient! I guess calculus isn’t so bad after all.
And that’s basically what backprop is doing. It goes backward through the network, calculating the negative gradient for each node, eventually combining them to give us our result. We can finally reduce the error and descend the mountain!
Lastly, we need to use the gradients we just got to actually change the weights and biases — using gradient descent. It uses the gradients to move down the error mountain, a little bit at a time.
Combined, these parts (forward propagation, error functions, backpropagation, and gradient descent) make up the training process.
Yay! We’re done! Right?
Not so fast — unfortunately, this needs to happen repeatedly for the net to learn. We’ll FINALLY end up with a net that can actually do things after hours and hours of training (maybe even weeks!)
Really time-consuming, but also incredible!
Some Problems…
The example we used is called an MLP (multilayer perceptron) — where each node is connected to each other node. They’re general purpose — trainable on text, audio, etc. — but aren’t really good at doing one task well.
If you tried to train an MLP on simple, clean images, it’ll actually do pretty well:
But, give it images with noise, random colours, and weird camera angles (like the photos most humans take 🤦♂️), and it absolutely bombs.
Why? Because MLP’s don’t understand images.
It sounds obvious when it’s written like that, but it can be hard to acknowledge when the net is correctly guessing image after image. The MLP doesn’t know what’s happening in the image, because we can’t stuff an image through a neural network — the net takes in numbers, not pictures.
So, we unroll the image into a vector (a vertical string of numbers) of raw, pixel values — into the language of computers.
As you’ve probably guessed, this causes lots of weird problems — the MLP can’t see the picture, just that certain pixel values relate to different outputs. They don’t know where the pixels are — just what they are. Because of this, if you give a random picture of noise to an MLP, you might actually get a confident answer. The MLP is really just memorizing — not learning.

To classify images, we need a net that can understand the image — just like our example associated cats with whiskers and dogs with snouts. MLPs can’t do that — but another network can.
That network is a CNN — a Convolutional Neural Network.
We need a Specialist.
While the name’s a mouthful, a CNN operates on basic concepts — and it’s all inspired by your eyes 👀.
Think about how you’re reading this article — you’re not reading everything at once. You’re (hopefully) reading letter by letter, word by word, one thing at a time, and then processing the information (unless you’re a bot reading an article about bots — get back to classifying images, procrastinator bot!)
That’s what CNNs do — scan images, one part at a time. Instead of eyes, they have kernels — tiny squares that pass over an image and transfer the information to the rest of our network. These kernels are a matrix of random numbers — they multiply the pixel values with them and send the output to the rest of the network.
All the kernels are inside a convolutional layer — special layers that process images (like detectives passing magnifying glasses over a photo). These specialist layers are connected to our best friends — MLPs (we missed you). The convolutional layers scan the image like a printer, and the MLP processes it. Your eyes are the convolutional layers, and your mind is the MLP.

But wait — what if the image isn’t divisible by how much you’re moving it over? Think about it — if your kernel is 3 pixels wide and 3 pixels long, and it’s moving two over on a 6 by 6 image, then it’s going to end up going beyond the image, into the eternal void 😲.
There are a couple ways to fix this — we can just pad or crop the image to the correct size. Or, if we’re feeling lazy, we can just let the network do its thing and replace the blank values with 0 — it shouldn’t affect our output too much.
Now, we can finally start training!
You knew it wasn’t that easy. There’s a slight problem with convolutional layers — if you have too many kernels going over a little too many images, inside a little too many layers…there’s a good chance your computer won’t survive. Too many computations!
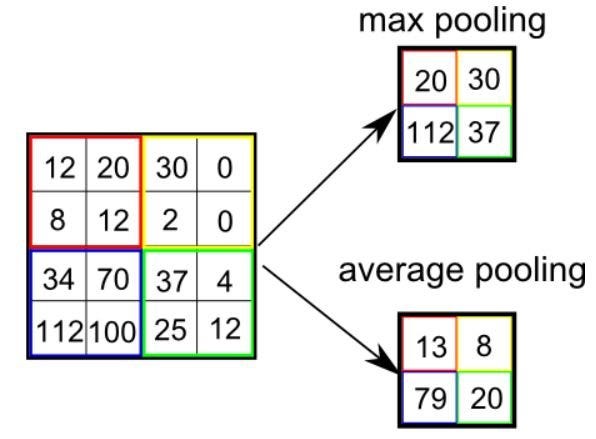
So, to prevent your computer blowing up, humans invented pooling layers — they make the kernel outputs smaller but keep (most) of the important stuff.
Think of you and your friend inside a pool, a mile apart (damn, that’s a big pool, and pun intended). If you got rid of all the water in between, you wouldn’t be losing anything valuable (yes water’s important, but just assume that it isn’t for now). Now, you can talk to your friend without using a satellite!
That’s what max pooling layers do — they pass another 2 by 2 kernels on top of the kernels (kernel inception 🤯), taking just the maximum value for every set of numbers it sees. For every 4 pixels, the pooling layer will replace them with just 1 (there’s also average pool that just takes the average of all 4, but we’ll ignore those for now).

Typically, CNNs have pooling layers after every convolutional layer — preventing the net from taking weeks to train, and your laptop from exploding.
The image goes through the convolutional and pooling layers, gets unrolled and put through the MLP, and comes out as what we were hoping for — a prediction!
Finally!
And that, is how CNNs work — neural networks for (mostly) images 📷.
But what if we need to classify characters in text? Or predict the weather? Or process stock prices? Then what do we do?
You’re going to make me do it, aren’t you? You’re going to make me explain recurrent neural networks, a special type of network that works with sequences and ordered data.
The Recurring Pain of Neural Networks.
RNNs are, by far one of the most powerful networks out there — all because they can remember things.
What? How?
If you were giving a presentation, you couldn’t just start talking — you would need to store and recall your research to give it. Luckily, our brains have that covered with memories, allowing us to make decisions based on past experience.
Robots aren’t that fortunate — MLPs and CNNs are good at understanding un-ordered (non-sequential) data but can’t use previous data to help with new data. Sound confusing? Let me explain.
Supposed that you’ve built a net to recognize random images, from trees to pencils. After training, you give it images of a squirrel, tree, bird, grass blade, and a flower to test — and the net classifies all of them correctly. For the moment of truth, you give it a cloud…which it intelligently labels as cotton candy, proving itself to be an absolutely phenomenal creation.
These mistakes are common with machine learning — but they feel unsolvable. The problem isn’t really our network (though it feels like it). Cotton candy and clouds do, in certain ways, look pretty similar — fluffy textures, rounded curves, and weird angles that make it hard for the net to find differences.
The reason we have no problem doing that (otherwise we’d be trying to eat clouds — yum) is because our minds are way more complex. They have enough power to find smaller details that nets might miss.
But, there’s also another reason — inferences. If we were given a bunch of images related to nature, then we would probably infer that the next one might be too. In other words, we can take past experiences into account when making new decisions — unlike nets, which just use them to change and learn architectures. We need nets to store and recall past information — allowing nets to make decisions based on context.
In other words, we need a memory.
Imagine how useful it would be for something like temperature, where each data point is related to the previous one. Humans can look at multiple data points and make trends, but traditional nets can only look at one point at a time — useless if the order of the points matters. There are hundreds of applications where this could be used — predicting stock precise, energy rates, paragraph writing, you name it.
And that’s where RNNs come in — nets that take the previous output and use it as the current input.

Here’s an example to clear things up.
If an RNN was classifying the images in the last example, it would use the previous images to guide it.
At first, it’s a raw network — there’s nothing to remember yet, almost like a newborn child.
As you show it the image of a plant though, it uses the data it got from the last image and uses that as an input — along with the picture of the plant.
Basically, it combines the last output with the current input to make a better prediction.
This kind of architecture allows our RNN to take the past data (in this case, a bird) into consideration when it makes a decision, enabling it to make connections between data! How sick is that?
There’s a problem though — RNNs don’t have the best memories. Like — really bad memories 😅.
Use them multiple times and they squish memories to save space, losing valuable information.
The solution to this problem (once again) lies in our minds — we don’t just save everything into one memory. We split it into short term for the “kind of” useful stuff, and long term for the things we really care about. Can we get RNNs to do the same thing — letting them keep more information?
Turns out that we can do that, with the help of a little something called LSTMs.
RNNs on Steroids (the last one, I swear)
Short for long-short-term-memory (try saying that three times fast), LSTMs are another special kind of neural network. They have 2 memories (long/short) and 4 gates to process them: learn, forget, update, and use.
Sounds complicated, but these networks are simple in practice.
The Learn Gate:
Takes the previous short-term memory and the current event and combines them.
It ignores some parts of both but keeps the important stuff.
The Forget Gate:
Takes the long-term memory and decides what to keep.
Is multiplied by a forget factor to decide how much gets eliminated.
The Remember Gate:
Takes the output of the learn and forget gate (events and memories) and adds them.
That’s pretty much it — really easy to remember 🤣
The Use Gate:
Where the actual learning occurs.
Takes new long-term memory, short term memory, and current event.
Puts it through our best friend — the MLP.
Takes useful parts and creates new long-term memory.

See, I told you that it wasn’t that complicated. LSTMs are like 4 smaller nets stacked on top, making a sort of inception-level network!
MLPs, CNNs, RNNs, and LSTMs — the four pillars of machine learning. More types obviously exist, but these are the building blocks — made up of stacked functions, trying to predict outputs based on inputs. And, specialized inputs need specialized outputs — CNNs for images, RNNs for sequences, and LSTMs for longer series data. That’s really what drives most AI today.
Looks like AI isn’t so black box after all!
Conclusion
You now probably agree that AI is pretty damn cool — but (like everything), it also has a couple problems. Mainly that it’s a little too good at achieving its goals, beating us at Go, Chess, and Jeopardy. It’s limited based on what we tell it do to and the goals we make.
Set the right goals, and it’s accelerated our species. The wrong ones, and you could cause war and disease.
Take a sword, for example. Placed in the hands of a soldier, it is a weapon of good. In the hands of a thief, and it’s a weapon of destruction. It’s not the sword that’s good or evil — just the intentions the wielder.
Similarly, AI is a tool — dependent on our intentions. Imagine using it to diagnose deadly disease — it could prevent human error that leads to 250 000 American deaths per year. Using it to drive cars — it could prevent millions of avoidable deaths.
Banning it would be a grave mistake — causing millions of preventable deaths and robbing us the chance to live better lives.
We don’t need to ban or demonize AI — we need to ensure it’s appropriate and sustainable development. Spreading knowledge, rather than ignorance.
Humans are capable.
AI is capable.
We just need to make sure that its goals are aligned with ours.
Takeaways:
AI is a new, incredibly capable technology that tries to learn from experience
The most basic form of AI is a Neural Network (MLP)– thousands of tiny functions strung together like the neurons in your brain.
CNNs are used for image classification, and “scan” an image to find things like edges and faces
RNNs are used for series data, where the order matters — it uses memories to inference
LSTMs are used for longer series data, where we need more memory (or if we just want better performance) — has both a long term and short-term memory
LSTMs have 4 gates — Learn, Use, Remember, Forget
AI can be used to change the world or destroy it — it’s up to our intentions
Thanks for reading the entire way though, I hope that you learned something! Give it a clap or two to appease the AIs behind Medium 😅
More about me here: adityadewan.com

{kind=link}